Large Language Models (LLMs) have rapidly transformed from an obscure technology into the driving force behind countless AI applications we interact with daily. From chatbots and virtual assistants to content creation tools and code generators, LLMs are revolutionizing how businesses leverage artificial intelligence. But what exactly are these powerful models, and how are they reshaping our technological landscape?
What Are Large Language Models?
At their core, LLMs are sophisticated AI systems trained on massive amounts of text data, enabling them to understand and generate human-like language with remarkable accuracy. These models are built on transformer architectures – neural networks specifically designed to process sequential data like text. Unlike traditional machine learning models that are typically designed for specific tasks, LLMs are a type of foundation model trained on vast corpora to discover patterns in language.
The breakthrough with LLMs is that they allow computers to analyze and understand human language naturally. Before their emergence, computers could only receive instructions rigidly through pre-set commands or user interfaces. Now, LLMs enable more intuitive human-computer interaction – you can simply tell the machine what you want in natural language, much like you would communicate with another person.
The Inner Workings of LLMs
Tokenization and Embeddings
When a large language model (LLM) processes text, it doesn’t directly understand words as humans do. Instead, it works through a series of transformations that convert human-readable text into formats that mathematical models can process.
Tokenization is the first crucial step in this process, where text is divided into smaller units called “tokens.” Think of this as breaking a sentence into puzzle pieces that the model can work with. LLMs can’t process raw text directly—they need a standardized way to convert varied human language into consistent units that can be represented numerically. Tokenization creates this standardized representation. Different approaches to tokenization exist.
- Word-level tokenization simply splits text at word boundaries, so “I love ice cream” becomes [“I”, “love”, “ice”, “cream”].
- Character-level tokenization treats each character as a token, turning “Hello” into [“H”, “e”, “l”, “l”, “o”].
- Modern LLMs typically use subword tokenization methods (like BPE, WordPiece, or SentencePiece) because they balance vocabulary size and representation flexibility. With subword tokenization, common words like “the” get their own token, while less common words get broken down—for example, “tokenization” might become [“token”, “ization”]. Rare words might be split into even smaller pieces or individual characters.
As a practical example, if we tokenize “I love eating peanutbutter and jelly” with a subword tokenizer, we might get [“I”, “love”, “eating”, “peanut”, “butter”, “and”, “jelly”]. But for a more uncommon word like “neurophysiology,” we might get [“neuro”, “physio”, “logy”].
After tokenization, each token is converted into a numerical representation called an “embedding.” (see Figure 1. Semantic Relationships in Embedding Space) This is where the model begins to capture meaning. An embedding is a dense vector (essentially a list of numbers) that places each token in a high-dimensional space—typically hundreds or thousands of dimensions. This is much more powerful than simply assigning each token an ID number because the position in this space captures semantic relationships, the distance between embeddings represents semantic similarity, and the direction can represent analogical relationships.
To visualize embeddings, imagine a 3D space where words are positioned. In this space, “dog” and “cat” might be close together since both are pets. “King” and “queen” might be separated by the same distance and direction as “man” and “woman,” capturing gender relationships. “Apple” might be equally distant from both “fruit” and “computer,” capturing its dual meanings. Real embeddings use many more dimensions to capture detailed relationships between words, but the principle remains the same.
During the pretraining phase, the model learns these embeddings by trying to predict words in context. Words that appear in similar contexts end up with similar embeddings. This is how the model learns, for instance, that “dog” and “cat” are similar without anyone explicitly teaching it animal categories. The embedding values are essentially neural network weights that are used for predicting the next token given the previous tokens.
Tokenization and embeddings work together as the input processing pipeline. The user’s text is broken into tokens, each token is converted to its corresponding embedding vector, these embeddings become the actual input to the neural network layers, and the model processes these embeddings through many layers of attention mechanisms. Eventually, the model predicts the next token based on this processed information. This entire process allows LLMs to work with language in a mathematical space where semantic relationships can be captured and manipulated through numerical operations.
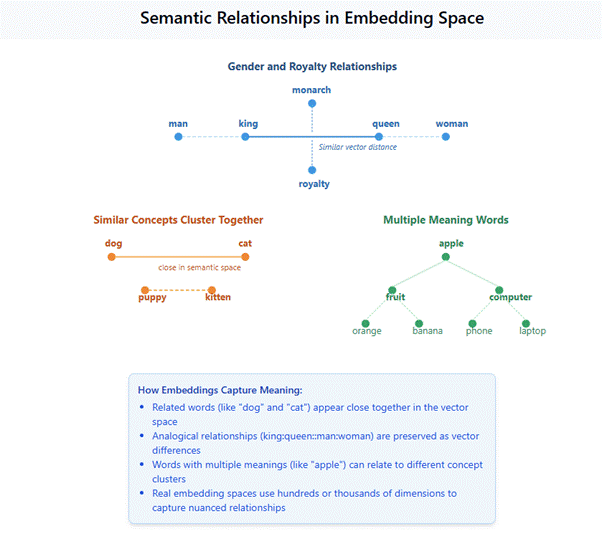
Figure 1. Semantic Relationships in Embedding Space
While the initial tokenization and embedding are fundamental, modern LLMs process these embeddings through complex transformer architectures with attention mechanisms that look at relationships between all tokens in the input. This is what allows them to maintain context across long passages of text and generate coherent responses. The entire procedure transforms human language into a form that mathematical models can process meaningfully, enabling the remarkable language capabilities of modern AI systems.
Transformer Architecture
The transformer architecture forms the backbone of modern language models, representing a revolutionary leap forward in natural language processing. Introduced in 2017 by Google researchers in their seminal paper “Attention Is All You Need,[1]” Transformers solved key limitations that plagued earlier approaches to language modeling. Unlike previous models that processed text sequentially—word by word like humans reading a sentence—transformers can process all words in a passage simultaneously, dramatically improving both speed and performance.
What makes transformers truly powerful are two innovative mechanisms (see Figure 2. How the Transformer Architecture works).
- Positional encodings: They solve a fundamental problem: when processing all words at once, how does the model understand word order? After all, “The dog chased the cat” and “The cat chased the dog” contain identical words but convey entirely different meanings. Positional encoding elegantly solves this by adding information about each word’s position directly into its representation, allowing the model to understand sequence without sequential processing.
- Self-attention mechanism: Think of attention as a spotlight that can focus on different parts of a text with varying intensity. When processing a word like “bank,” the model needs to understand whether it’s referring to a financial institution or the side of a river. The self-attention mechanism allows the model to look at other words in the context—like “river” or “account”—and adjust its understanding accordingly. This mimics how humans use context to disambiguate word meanings and represents a fundamental breakthrough in language understanding.
The journey of an LLM begins with pre-training on vast text datasets—often containing trillions of words drawn from books, articles, websites, and other text sources. This initial learning phase resembles how children acquire language through massive exposure to examples. During this stage, the model develops an implicit understanding of grammar, facts about the world, and the patterns and structures that characterize language. The model learns that certain words tend to appear near each other, that sentences follow particular patterns, and that language has hierarchical organization.
A crucial insight about LLMs involves how they generate text. And it seems that one of the most crucial parts of their generative function is based on their ability to correctly predict the next token given a sequence of tokens before. This prediction mechanism might seem basic—essentially a sophisticated form of autocomplete—but when implemented at massive scale with billions of parameters, it produces systems capable of generating remarkably coherent and contextually appropriate text.
The term “parameters” refers to the adjustable values within the neural network that store the model’s acquired knowledge—essentially the weights and connections that encode what the model has learned. These parameters are what allow the model to make predictions about language. The number of parameters has become a common metric for measuring an LLM’s complexity and potential capabilities. Modern language models operate at truly enormous scales—newly released Meta’s Llama 4 model, for instance, comes in versions with 109 billion and 400 billion parameters[2]. Other leading models contain hundreds of billions of parameters, with some approaching the trillion parameter mark.
This massive scale directly contributes to the impressive capabilities of modern LLMs but also creates significant computational challenges. Training these models demands specialized hardware like Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs), often arranged in clusters containing thousands of units. The energy consumption and computational resources required are substantial, with training runs for the largest models potentially costing millions of dollars in computing resources. This scale has made developing cutting-edge LLMs increasingly the domain of large technology companies and well-funded research labs that can afford the necessary infrastructure.
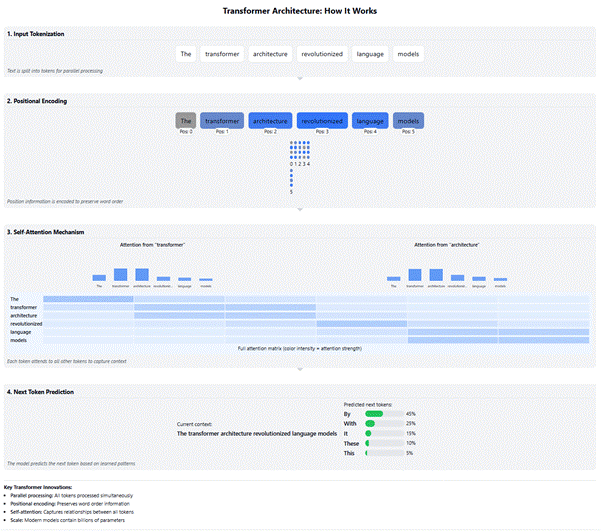
Figure 2. How the Transformer Architecture works
The advancement from early language models to today’s sophisticated systems represents a perfect example of how quantitative scaling—simply making models bigger and training them on more data—can lead to qualitative leaps in capability. As models grow, they don’t just perform the same tasks better; they develop entirely new abilities that weren’t explicitly programmed. This phenomenon, sometimes called “emergence,” helps explain why modern LLMs can perform so many diverse language tasks despite being trained primarily on the seemingly simple objective of predicting the next word in a sequence.
Business Transformations Powered by Large Language Models
The sophisticated neural architecture of Large Language Models unlocks a remarkable array of capabilities that are revolutionizing how businesses operate across virtually every sector of the economy. These capabilities represent not merely incremental improvements to existing processes but fundamentally new approaches to information management, content creation, and customer interaction. As we explore these applications, we’ll see how LLMs are transforming business operations at their core.
Content Creation and Generation: Amplifying Human Creativity
Text generation and content creation stand among the most immediately valuable applications of LLMs in business contexts. These models can produce remarkably human-like content ranging from marketing copy and product descriptions to detailed reports and creative narratives.
Unlike rule-based content generation tools of the past, modern LLMs can adapt their writing style, tone, and complexity to match specific requirements. For instance, a marketing team might use an LLM to generate dozens of variations of social media posts promoting a new product, each tailored to different platforms and audience segments.
This capability doesn’t replace human creativity but rather amplifies it, allowing creative professionals to explore more possibilities and refine their work more efficiently. Content creators can focus on strategic direction and creative vision while using LLMs to handle more routine aspects of production.
Semantic Search: From Keywords to Understanding Intent
Search capabilities have undergone a profound transformation through LLM integration. Traditional keyword-based search simply matched terms and ranked results based on factors like page authority or relevance scores. LLM-enhanced search, by contrast, understands the semantic intention behind queries and can provide direct answers rather than just links to potential information sources.
When a business user searches for information about “Q2 revenue growth for European markets,” an LLM-powered system doesn’t just return documents containing those terms—it can extract the specific information, synthesize data from multiple sources, and present a coherent, contextual answer. This capability dramatically reduces the time knowledge workers spend hunting for information across corporate databases and documents.
The shift from “search” to “answer” represents a fundamental change in how employees interact with corporate knowledge, making information discovery faster and more intuitive.
Language Translation: Breaking Down Global Barriers
Translation and cross-language communication have advanced from curiosities to mission-critical business tools with the advent of LLMs. Earlier machine translation systems often produced awkward, sometimes incomprehensible results that required substantial human editing.
Modern language models can translate between hundreds of language pairs with remarkable fluency, preserving not just the literal meaning but often the tone and cultural nuances of the original text. This enables businesses to operate globally with unprecedented ease, supporting real-time communication in multilingual meetings, instantaneous translation of documents and websites, and culturally appropriate marketing across diverse markets.
The ability to communicate naturally across language barriers opens new markets and collaboration opportunities that were previously hindered by linguistic constraints.
Software Development: Accelerating the Coding Process
For software development teams, LLMs have emerged as powerful productivity multipliers through code generation and analysis capabilities. These models can draft entire functions based on natural language descriptions, complete partial code blocks, convert between programming languages, and explain complex algorithms in plain language.
A developer might describe a desired feature e.g., “Create a function that validates email addresses using regex and returns a boolean result” and receive working, properly formatted code ready for integration. Beyond generation, LLMs excel at code review, identifying potential bugs, security vulnerabilities, and performance issues before they reach production environments.
This transformation is particularly significant because it democratizes software development, allowing domain experts with limited programming experience to create and modify code with natural language guidance.
Data Intelligence: Extracting Meaning from Unstructured Information
The data analysis landscape has been similarly transformed by LLMs’ ability to extract meaning from unstructured text data. Businesses generate vast amounts of textual information through customer feedback, support tickets, social media mentions, and internal communications. Traditional analysis methods struggled to derive actionable insights from this unstructured data.
LLMs can now analyze sentiment at scale, identify emerging issues from support tickets, extract competitive intelligence from market communications, and surface patterns that would be impossible for human analysts to detect manually. This turns previously underutilized text data into a strategic asset for decision-making.
The ability to process unstructured text at scale means businesses can now incorporate a much wider range of inputs into their decision-making processes, leading to more informed and nuanced strategies.
Conversational AI: The New Face of Customer Interaction
Perhaps the most visible and widely adopted application of LLMs is in conversational AI systems that power customer service chatbots, virtual assistants, and interactive knowledge bases. Unlike earlier generations of rule-based chatbots that followed rigid scripts and frequently frustrated users, LLM-powered conversational systems can understand complex queries, maintain context across multi-turn conversations, and provide detailed, helpful responses.
These systems can handle routine customer inquiries with human-like understanding, escalate complex issues to human agents when appropriate, and continuously learn from new interactions. For businesses, this translates to improved customer experiences, reduced support costs, and the ability to provide consistent, high-quality service at any scale.
What makes these conversational systems truly revolutionary is their ability to understand context and nuance in ways that previous generations of automated systems could not, creating interactions that feel genuinely helpful rather than frustratingly limited.
Strategic Implications: Rethinking Business Intelligence
The integration of LLMs into business processes represents more than just improved efficiency—it signals a fundamental shift in how organizations process information and make decisions. As these technologies mature, several key strategic implications emerge:
- Knowledge Democratization: LLMs make specialized knowledge more accessible throughout organizations, allowing employees at all levels to leverage insights that were previously confined to experts.
- Workflow Transformation: Business processes that were constrained by information processing bottlenecks can now be reimagined with LLM capabilities at their core.
- Skill Evolution: The most valuable employee skills are shifting from information gathering and basic analysis to prompt engineering, result evaluation, and strategic application of AI-generated insights.
- Competitive Landscape: Early adopters who effectively integrate LLMs into their operations are gaining significant advantages in efficiency, innovation, and customer engagement.
The Path Forward
As LLMs continue to evolve, their integration into business operations will likely deepen and become more sophisticated. Organizations that develop literacy around these technologies—understanding not just how to use them but when and where to apply them most effectively—will be best positioned to thrive in this new landscape.
The most successful implementations will be those that thoughtfully integrate LLMs into workflows where their strengths complement human expertise rather than attempting to replace it entirely. By viewing these technologies as collaborative tools that enhance human capabilities rather than substitutes for human judgment, businesses can unlock their full transformative potential while mitigating their limitations.
The trajectory is clear: LLMs are rapidly becoming essential components of the modern business technology stack, transforming how organizations create content, serve customers, develop products, and make decisions. As these technologies continue to mature, their business impact will only grow—making a deep understanding of their capabilities and optimal applications not merely advantageous but increasingly essential for competitive success.
[1] https://arxiv.org/abs/1706.03762
[2] https://www.llama.com/docs/model-cards-and-prompt-formats/llama4_omni/